3台r720搭建pve9集群并安装ceph过程记录
记录学习安装pve9下集群创建及ceph安装配置。
一、规划
1.1 设备硬件
3台主机系统型号:PowerEdge R720
每台主机使用1块300g机械盘作为系统盘安装pve9,一块250g sata ssd作为db/wal磁盘,2块3tb机械硬盘作为数据盘osd。
另外2快1000M网卡bond作为集群网络,后续会升级为10G网卡。
1.2系统IP地址规划
| 名称 | IDRAC地址 | pve主机地址 | ceph集群地址 | pve集群地址 | 服务标签 |
|---|---|---|---|---|---|
| pve1 | 192.168.0.101 | 10.139.27.101 | 10.0.0.101 | 20.0.0.101 | 2D3B232 |
| pve2 | 192.168.0.102 | 10.139.27.102 | 10.0.0.102 | 20.0.0.102 | 8285232 |
| pve3 | 192.168.0.103 | 10.139.27.103 | 10.0.0.103 | 20.0.0.103 | F9Z6232 |
1.3 pve9 换源
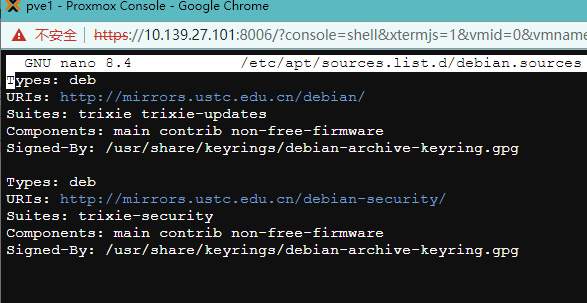
1.3.1、先换debian13 系统源
1 | #修改基础系统(Debian)的源文件 下面两个命令替换 Debian 官方源和安全更新源。 |
1.3.2、替换pve的无订阅源
1 | #修改 Proxmox 的源文件 换源 |

1.3.3、修改ceph源(安装ceph后)
1 | #修改 ceph 源文件 换源 |
1.3.4、ct源
1 | sed -i.bak 's|http://download.proxmox.com|https://mirrors.ustc.edu.cn/proxmox|g' /usr/share/perl5/PVE/APLInfo.pm |
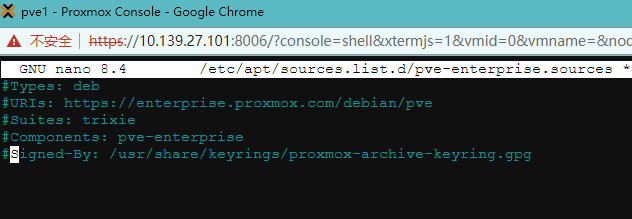
1.3.5、注释企业源
不注释掉更新时会报错nano /etc/apt/sources.list.d/pve-enterprise.sources
1.4、更新
apt update&&apt dist-upgrade
或者apt full-upgrade -y
二、pve集群三张网络
2.1 介绍
生产环境网络推荐三网互相分离,但在非关键业务情况如我现在测试环境下可以将集群网络与公共网络合并。但是绝对不建议将ceph网络与其他网络合并共用。
2.1.1. 集群网络 (Cluster Network)
主要功能:
节点间心跳检测和集群状态同步
虚拟机迁移(Live Migration)数据传输
集群配置变更同步
Quorum(法定人数)维护
流量特点:
数据量相对较小,但对延迟和可靠性要求极高
心跳包很小但必须及时送达
迁移时会有大流量突发
2.1.2. 公共网络 (Public Network)
主要功能:
Web管理界面访问(端口8006)
API调用和管理操作
虚拟机对外服务流量
用户访问虚拟机的网络
流量特点:
面向用户,流量类型多样
可能包含大量外部访问流量
安全性要求较高(暴露给外部)
2.1.3. Ceph 网络 (Ceph Network)
主要功能:
Ceph OSD 之间的数据复制和心跳
Ceph MON 节点间的通信
客户端与 Ceph 集群的数据读写
数据重新平衡和恢复流量
流量特点:
带宽需求极大(特别是写入操作)
对延迟敏感,直接影响存储性能
几乎持续有后台数据同步流量
2.2 网络合并的影响
根据deepseek介绍
网络合并的性能瓶颈:
| 合并方案 | 主要风险 | 性能影响 |
|---|---|---|
| Ceph + 集群网络 | 存储复制影响迁移 | 迁移速度下降 50-80% |
| Ceph + 公共网络 | 用户流量影响存储 | IOPS 下降 30-70% |
| 三网合一 | 所有流量相互干扰 | 整体性能下降 60-90% |
实际测试数据对比:
| 场景 | 迁移速度 | Ceph IOPS | 网络延迟 |
|---|---|---|---|
| 三网分离 (25GbE) | 8 GB/s | 80,000 | 0.1ms |
| 集群+公共合并 (10GbE) | 3 GB/s | 45,000 | 0.3ms |
| 三网合一 (10GbE) | 1 GB/s | 15,000 | 1.5ms |
生产环境中,强烈建议三张网络物理分离,特别是 Ceph 网络必须独立。如果预算或硬件限制,可以按以下优先级合并:
第一优先独立:Ceph 网络(存储性能关键)
第二优先独立:集群网络(稳定性关键)
可适当共享:公共网络(可与其他业务流量共享)
2.3优先创建ceph集群网络
2.3.1创建linux bond
从属里输入网卡3、4名称,将这2个网口聚合,选lacp,一会要到交换机上设置,这里暂时不管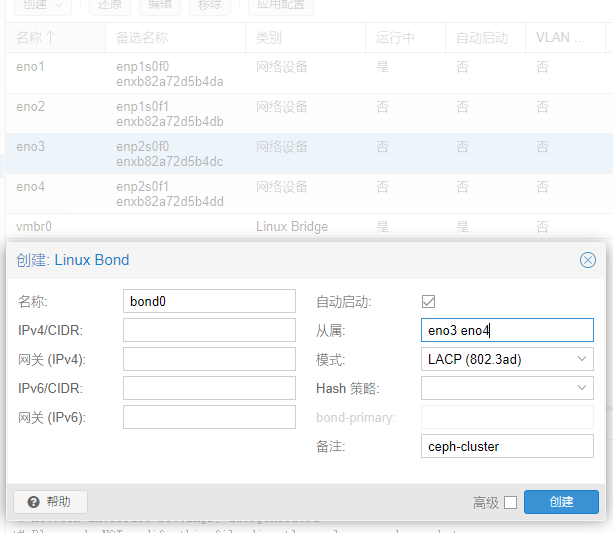
然后创建linux bridge桥接到bind0上并配置ceph集群网段地址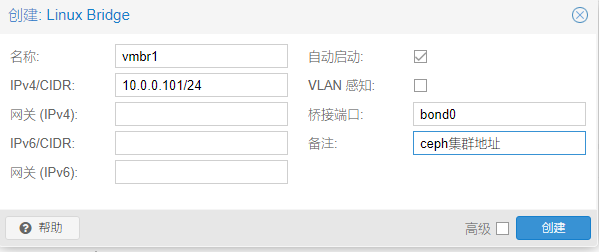
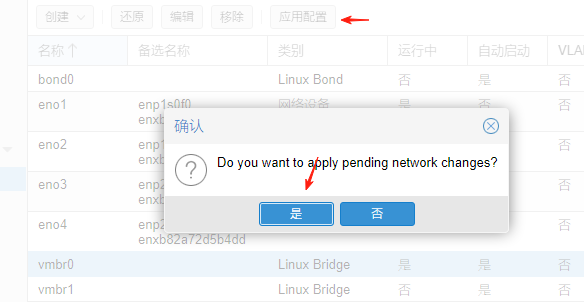
2.3.2交换机配置链路聚合lacp
1 | # 创建vlan1999用于ceph集群使用 |

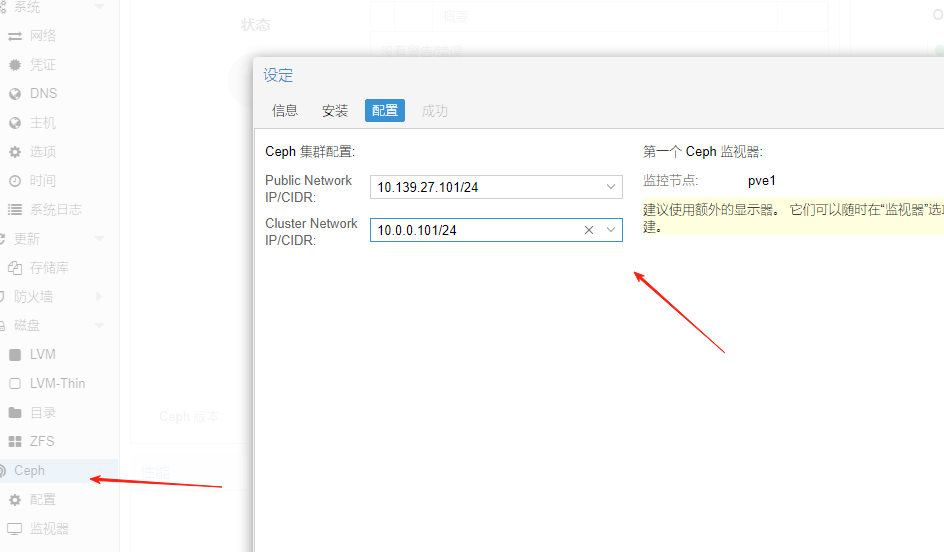
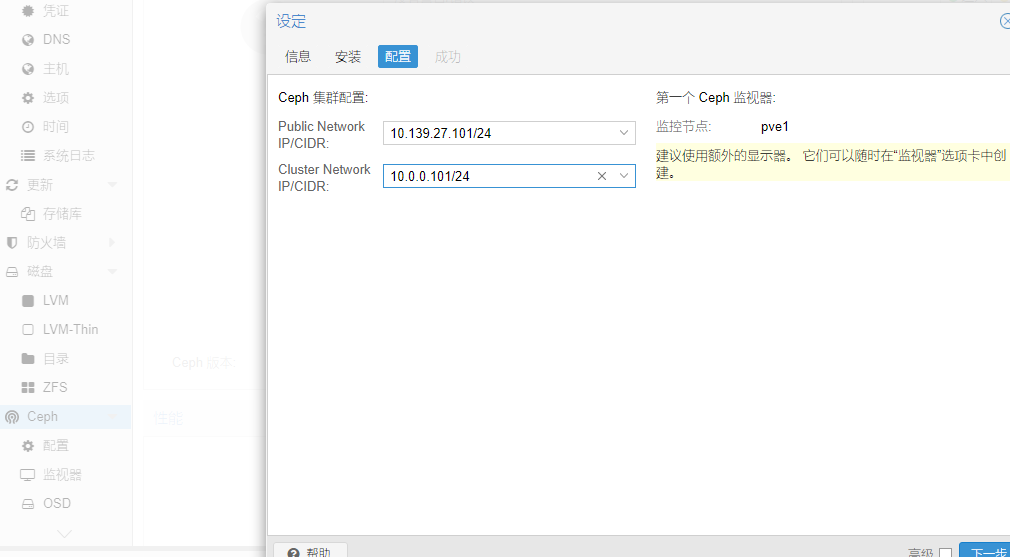
2.3.3配置ceph
指定公共网络地址和集群地址
2.4 public network和cluster network
这里将网口1、2做链路聚合
交换机上提前创建vlan1998用于pve集群网
配置聚合组为trunk模式并放行vlan1 vlan1998
以命令行方式配置公共网和集群网地址nano /etc/network/intefaces
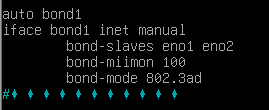
创建
vmbr0用于public网络(vlan1)
vmbr2用于集群网(vlan1998)
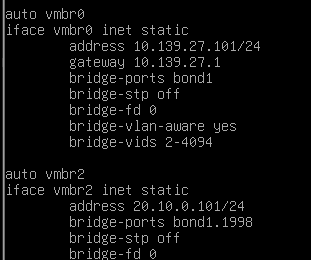
bond-miimon 100 是 Linux Bonding 驱动中一个链路监控参数,用于检测网络接口的物理连接状态。
vmbr0这里误勾选了vlan感知,后续会取消。所以最后2行参数无视即可。
也可以通过web配置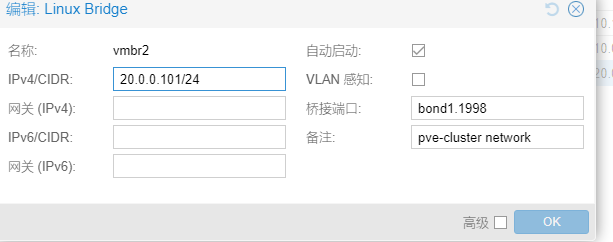
1 | #重启网络服务 |
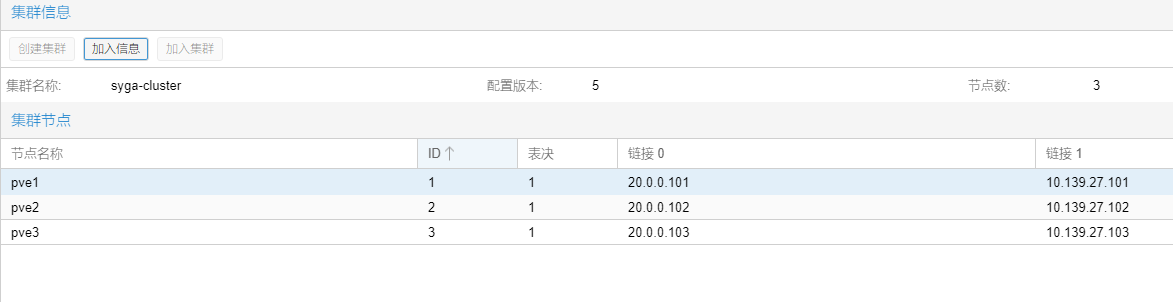
三、创建pve集群
3.1 pve1创建集群
先在pve1主机上,选择“数据中心”–选择“集群”-选择“创建集群”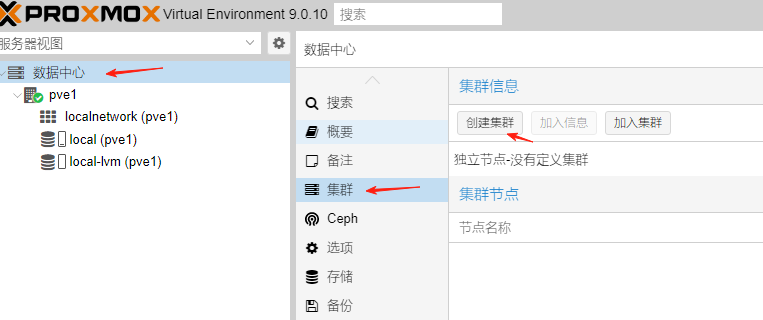
我们先使用public公共网络,后期视情况添加备用集群专用网络并调整优先级或者直接删除public network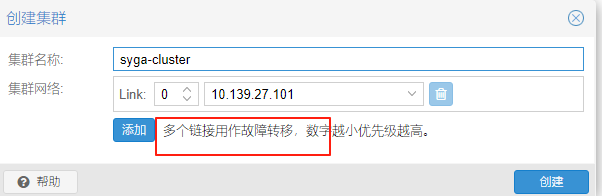
创建成功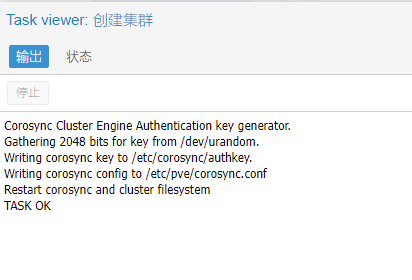
点击加入信息,复制信息备用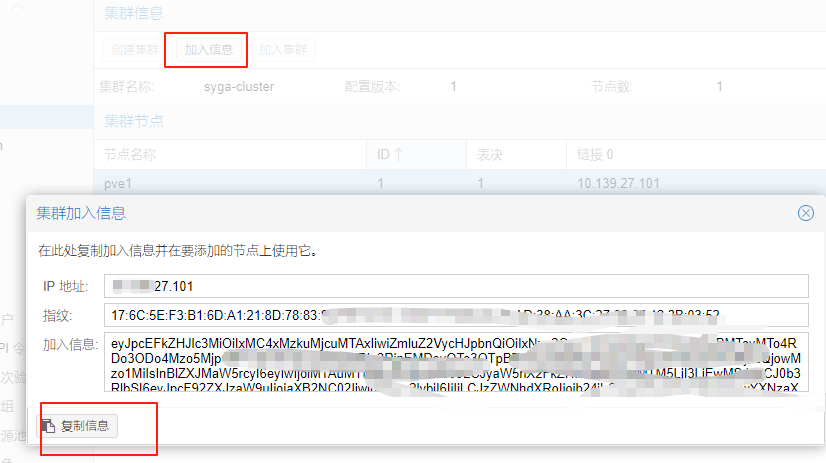
3.2 pve2 pve3加入集群
依次登录pve2主机和pve3主机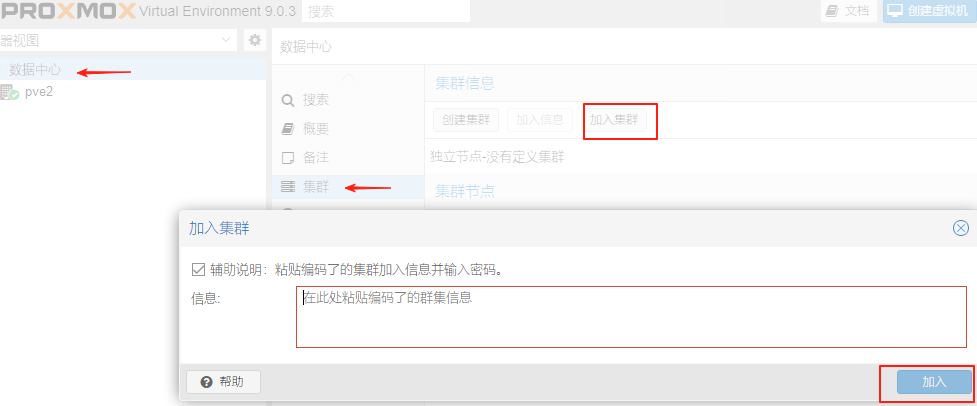
将pve1主机上的加入信息复制到上面方框内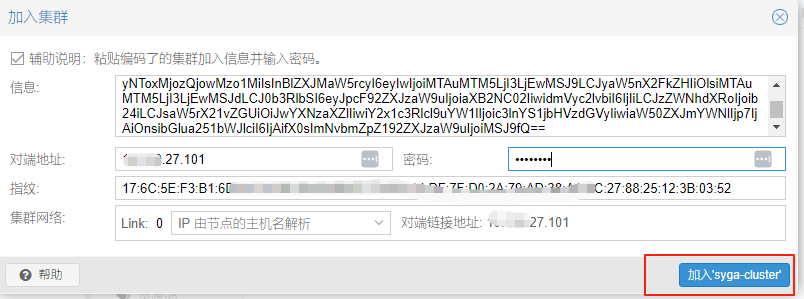
输入pve1的root密码并点击加入集群
这里会提示下面内容,这是因为没有独立的集群网络,而共用public网络造成的
1 | Establishing API connection with host '10.139.27.101' |
3.3 删除集群节点
因为主机新增了集群网络,所以需要将pve2 pve3从当前集群删除。
目前9.0版本不支持从web删除,需要使用登录进shell终端执行以下命令
前提:待删除节点的虚拟机和数据全部备份迁移
3.3.1 登录到待删除集群节点上操作
按以下步骤依次在各节点上操作。以pve2为例
1 | #停止pve集群服务 |
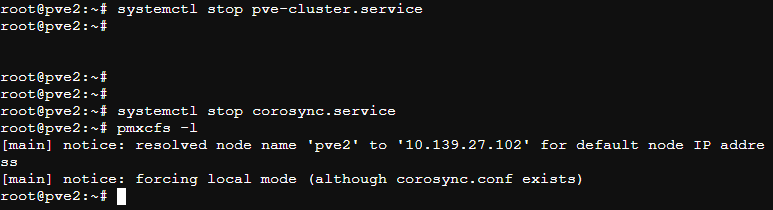
这时可以在待删除节点pve2上只能看到本机了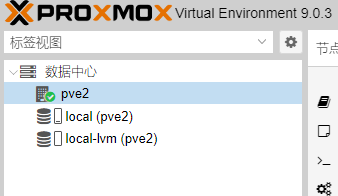
但是在pve1和pve3上还能看到离线状态的pve2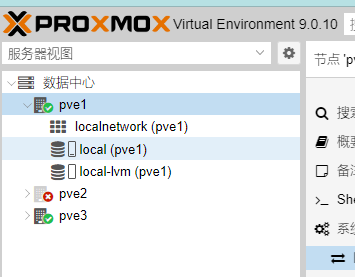
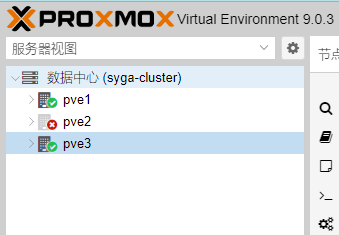
补充:删除pve2上的集群节点数据
1 | cd /etc/pve/nodes |
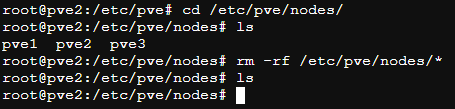
3.3.2 登录到pve1主节点删除相关数据
此时pve2 pve3在pve1 web上显示均已离线
但是shell下用命令查看已经没有这2个node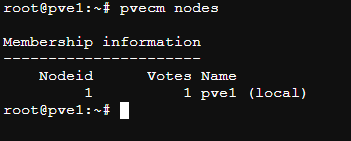
像删除pve2 pve3那样在pve1上操作pvecm delnode pve2
ps:pve1上该命令执行后pve3上的文件夹没了,不需要但是单独删除/etc/pve/nodes/*
ps:以下清除慎用,我删除后节点访问不了了。重启后解决。
1 | # 删除集群数据库 |
3.4 重新创建独立集群网络的集群
这里是一20段地址作为集群网络,同时把public网段也作为备用了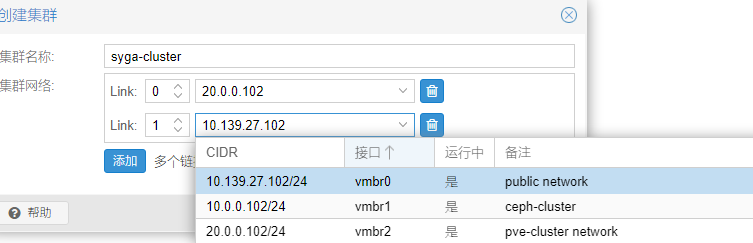
pve2上加入,这里选错对端地址了,崩溃,又要删除重加入了,这里就不赘述了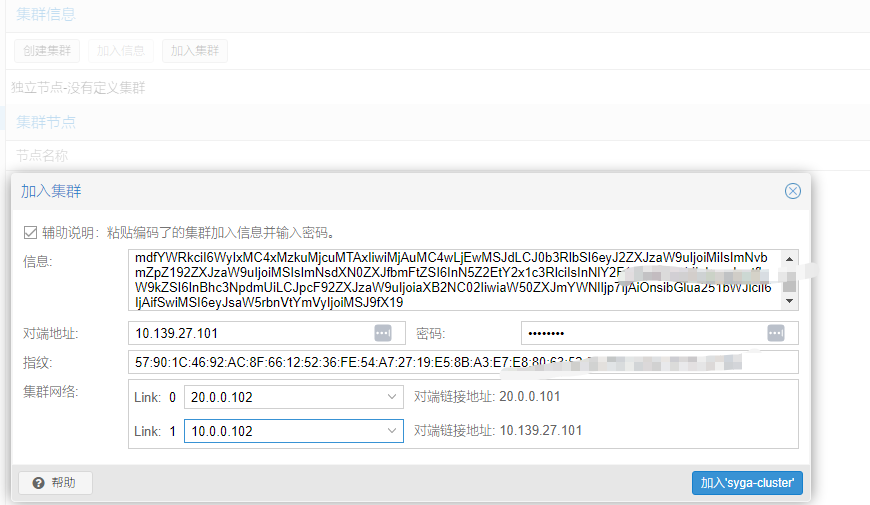
四、搭建ceph
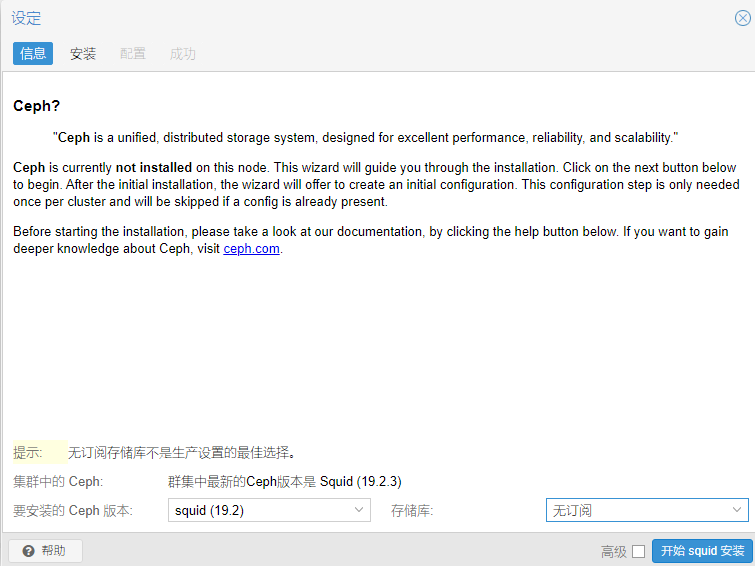
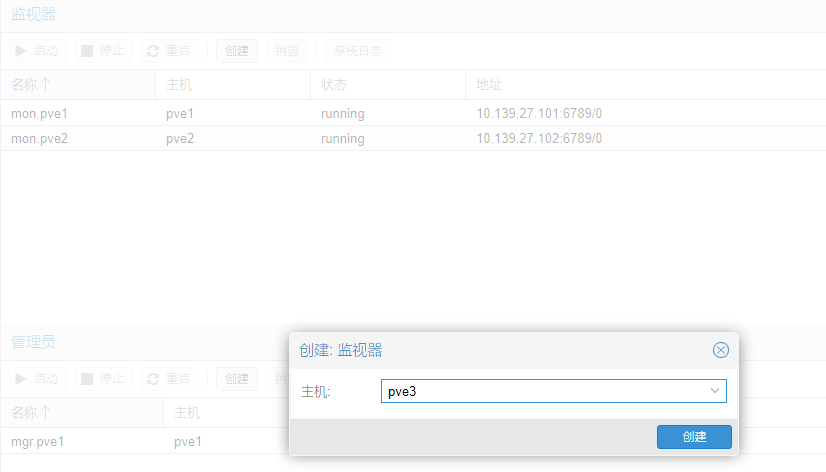
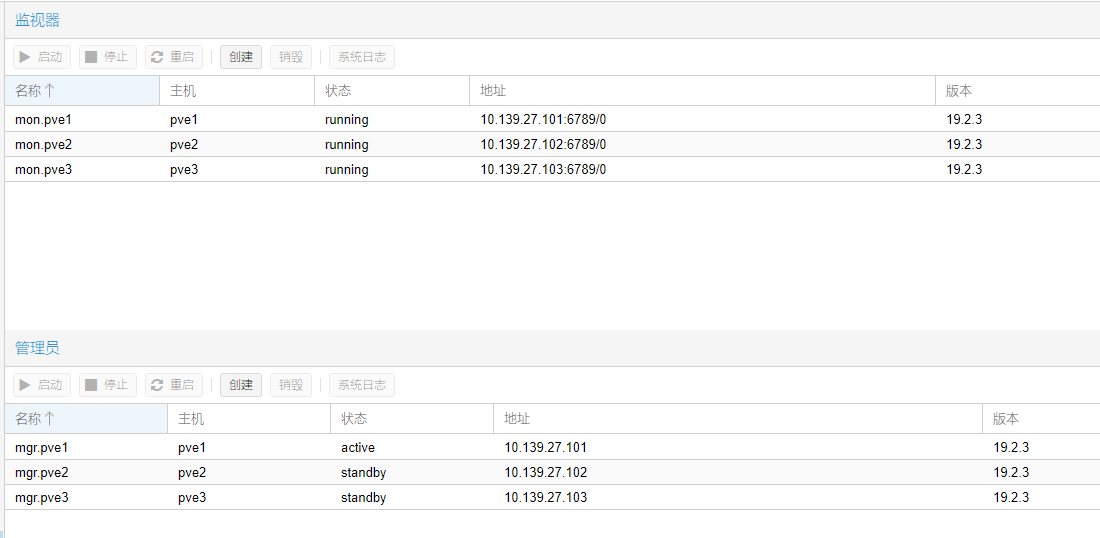
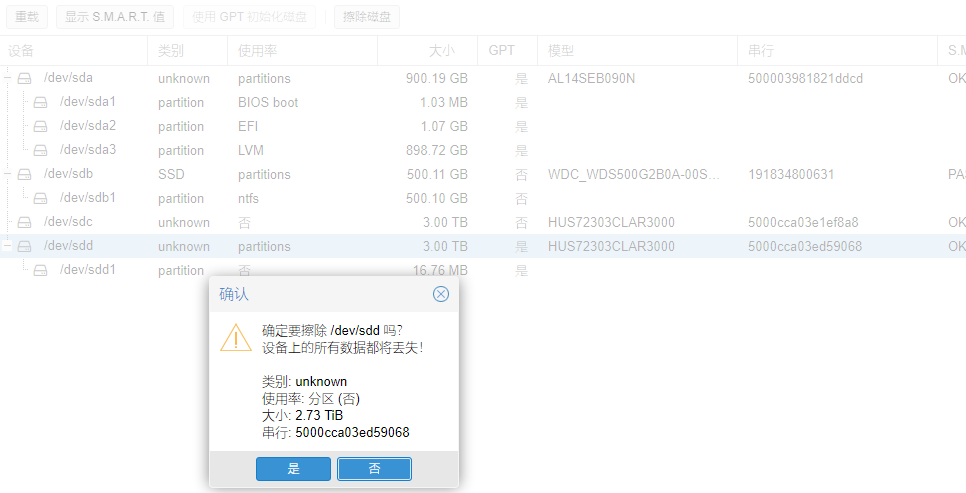
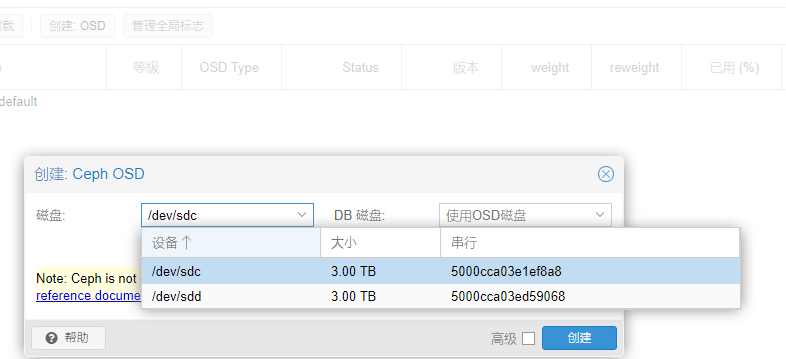
创建osd
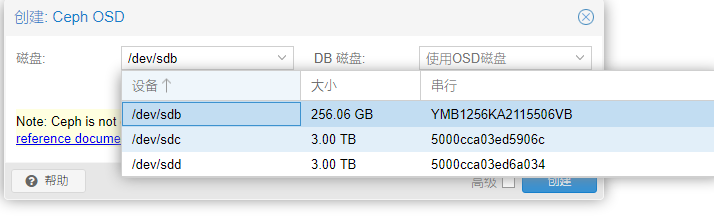
配置osd的db磁盘使用ssd,并且大小100g
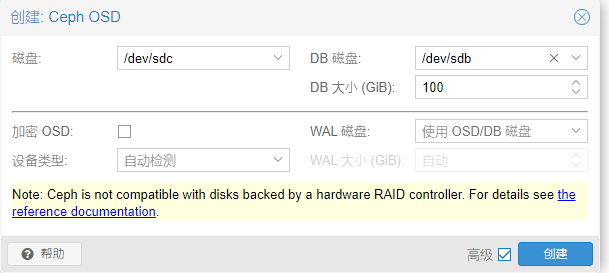
关键点:
Ceph 官方推荐:
DB 大小 ≈ 数据磁盘容量的 4%
3TB × 4% = 120GB
WAL 需求很小:5-10GB 足够用于 3TB 机械硬盘
256GB SSD 完全足够:可以同时容纳 DB + WAL
推荐配置:WAL 和 DB 在同一 SSD,简化管理
性能足够:对于大多数工作负载,WAL 和 DB 在同一 SSD 性能良好
创建osd后要创建资源池(默认rbd),否则无法调用
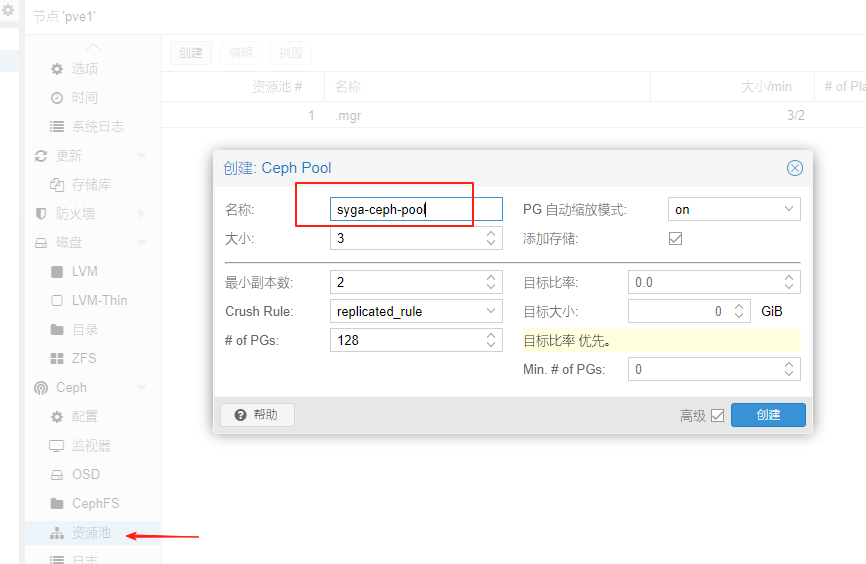
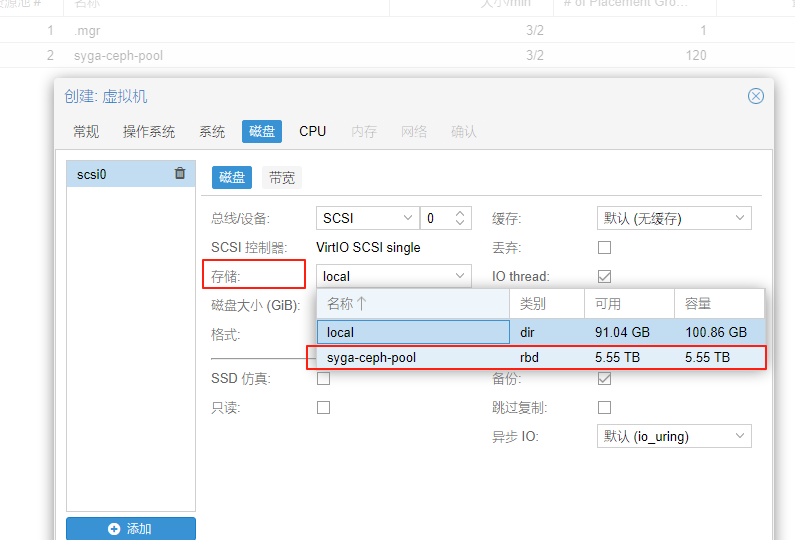
2025-9-28待处理:
一台主机内存插槽6故障需排查 已完成
pve3配置网络 已完成
pve2的聚合3配置 已完成
删除集群重建
pve2 3 的管理网口是共用nic1,一旦nic1做聚合后trunk,idrac网络就断了 已完成
2025-9-29
测试ceph性能
磁盘性能测试
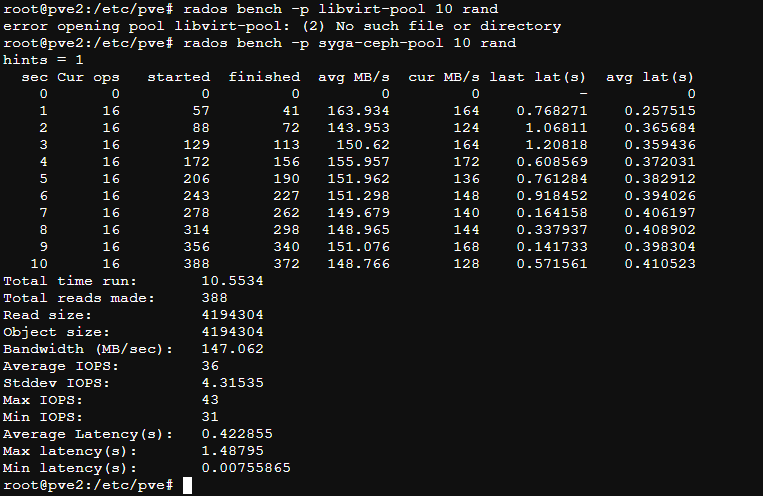
测试10秒钟写性能
rados bench -p syga-ceph-pool 10 write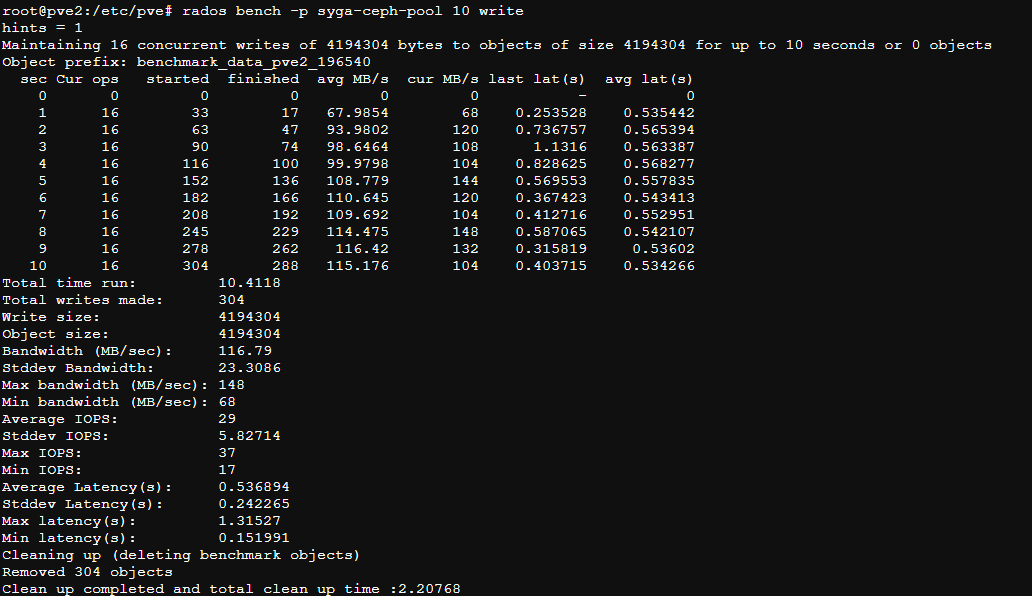
rados语法如下:rados bench -p <pool_name> <seconds> <write|seq|rand> -b <block size> -t --no-cleanup
-p: -p或-poo指定池名.
-b: 块大小,默认情况下块大小为4M。
-t: 并发线程数;默认值为16
–no-clean up:由rados工作台写入池的临时数据,不被清除。当这些数据与顺序读取或随机读取一起使用时,它们将被用于读取操作。默认情况下数据会清理。
1 | #参考链接https://www.modb.pro/db/471775 |
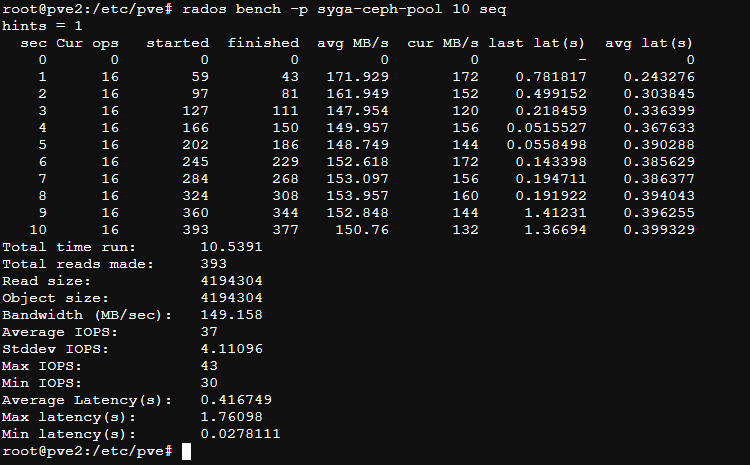
清除测试文件

rados load-gen
是CEPH提供的另一个测试工具, 像它的命名一样,rados load-gen 工具能用来在Ceph cluster上生成负载和用于模拟高负载场景
1 | rados -p syga-ceph-pool load-gen --num-objects 200 --min-object-size 4M --max-object-size 8M --max-ops 10 --read-percent 0 --min-op-len 1M --max-op-len 4M --target-throughput 2G --run-length 20 |
以上命令报错提示命令没找到,原因是复制到shell里多了好多空行。换成下面的正常了
1 | rados -p syga-ceph-pool load-gen \ |
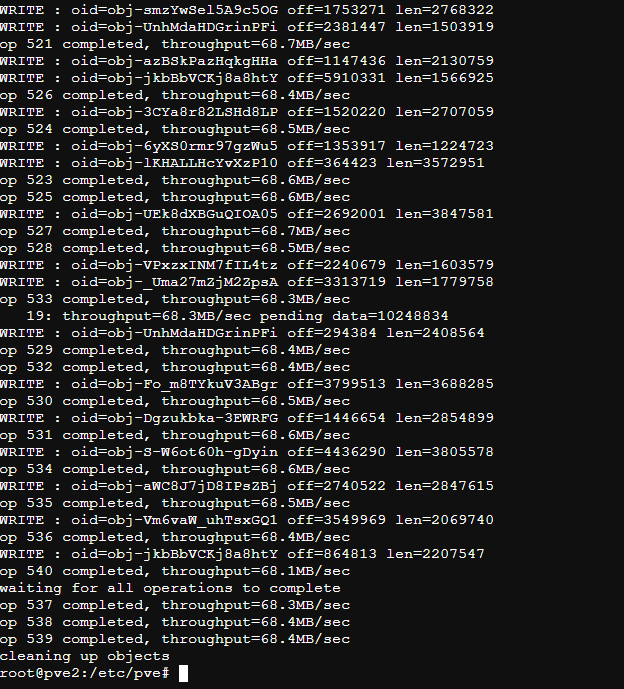
或者以下命令
1 | rados -p syga-ceph-pool load-gen --num-objects 200 --min-object-size 4M --max-object-size 8M --max-ops 10 --read-percent 0 --min-op-len 1M --max-op-len 4M --target-throughput 2G --run-length 20 |
rados -p
–num-objects: 生成测试用的对象数,默认 200
–min-object-size: 测试对象的最小size,默认 1KB,单位byte
–max-object-size: 测试对象的最大size,默认 5GB,单位byte
–min-ops: 最小IO操作数,相当于iodepth
–max-ops: 最大IO操作数,相当于iodepth
–min-op-len: 压测IO的最小operation size,默认 1KB,单位byte
–max-op-len: 压测IO的最大operation size,默认 2MB,单位byte
–max-backlog: 一次提交IO的吞吐量上限,默认10MB/s (单位MB)
–percent: 读操作所占的百分百
–target-throughput: 目标吞吐量,默认 5MB/s (单位MB)
–run-length: 运行的时间,默认60s,单位秒
两次命令对比

五、esxi虚拟机迁移到pve
千兆网络太慢了,万兆起步。
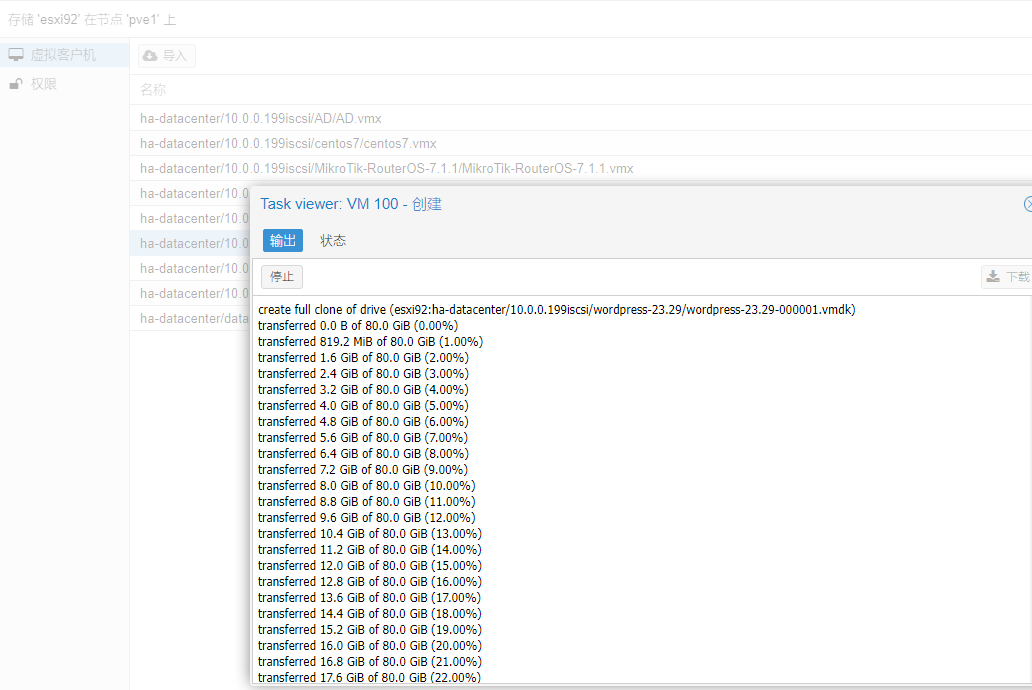

3台r720搭建pve9集群并安装ceph过程记录

