飞牛阵列掉盘,提示存储空间已移除
飞牛的存储空间还是不太适合求稳的企业个人,频繁的每周更新也可能是造成硬盘存储空间报错的原因之一(需要重启)。
下面简单记录下我的飞牛存储修复过程。
起因:
某次更新重启后发现用于pt数据的存储空间2提示“存储空间已移除,请。。。。”,我检查后发现10块硬盘都是正常连接的,也可以被正常识别,硬盘状态也没有告警。搜索论坛发现,不少用户都遇到过这个故障,有的人重启几次就解决了,可惜我重启无法解决。扒了下论坛这篇帖子,根据大佬的思路尝试修复成功。
分析:
飞牛的软raid功能和其他老牌nas软件比还是有一定差距。此外每次硬件重启后硬盘的编号会随机变化,同一块硬盘这次在fdisk -l里显示sda,下次可能叫sdb。。。。
之所以丢盘,应该是重启过程中每块数据盘的数据没有完全同步,导致同一阵列下的硬盘状态不同,而飞牛机制错认为这些没同步完成的硬盘出现故障了。。。
所以硬盘应该是没坏,而是阵列数据同步没有完成造成的软件故障,这可能和飞牛升级后默认立即重启也有一定关系,如果可以延迟重启或者暂不重启,或许可以大幅降低此类故障。
实战步骤如下:
查看阵列状态
mdadm -Ds

其中md127就是被移除的存储空间,显示inactive了
查看阵列内磁盘状态
lsblk -fp
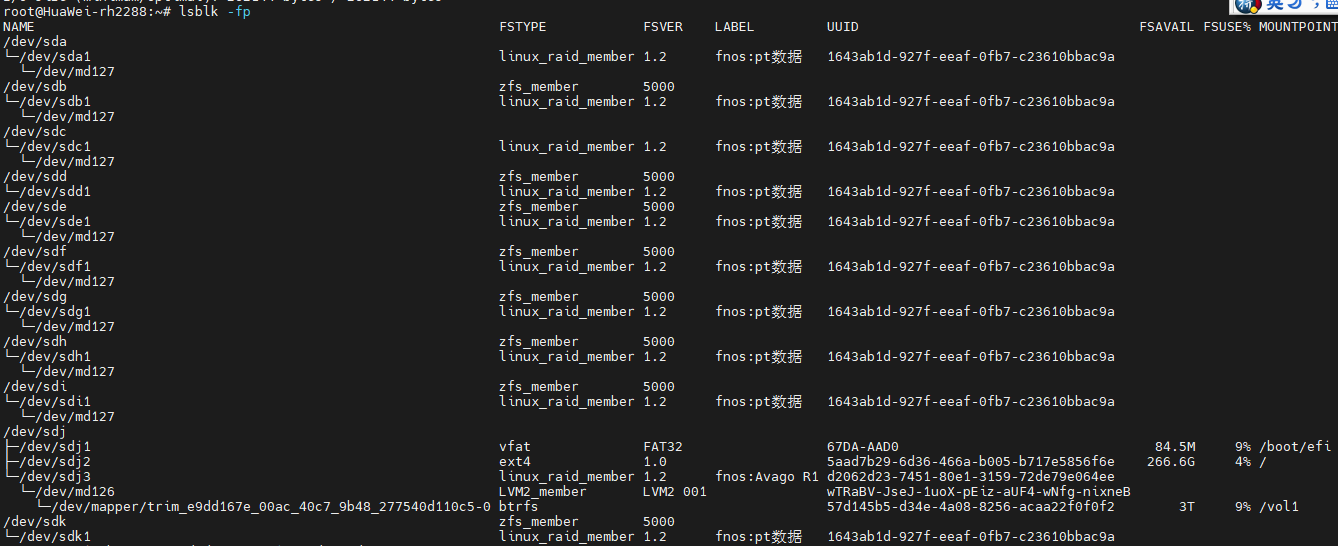
这里可以看到md127内有8块硬盘,其中sdk sdd被剔除在md127之外了。按道理md127是raid6,是支持2块硬盘故障的。再具体看下这8块硬盘的events
mdadm --examine /dev/sda1
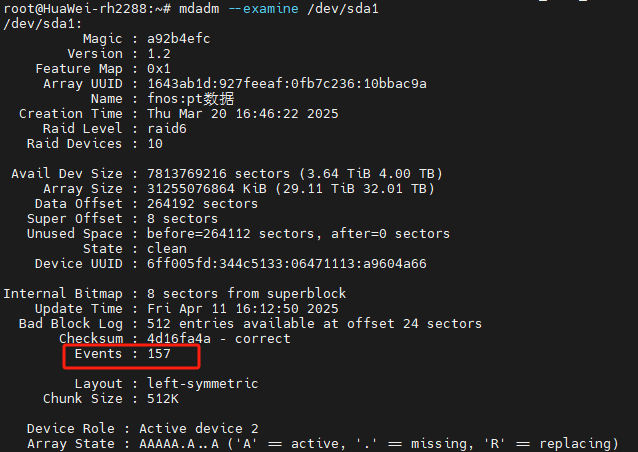
可以看到events是157 ,md127内各硬盘基本都是157,除了sdf(156) 以及另外2块sdd(137)和sdk(4)
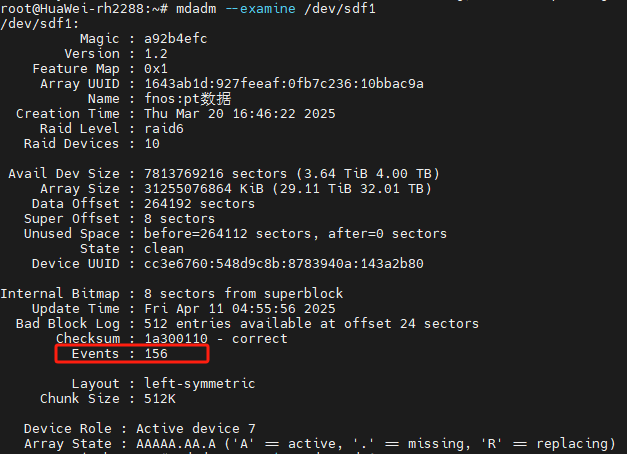
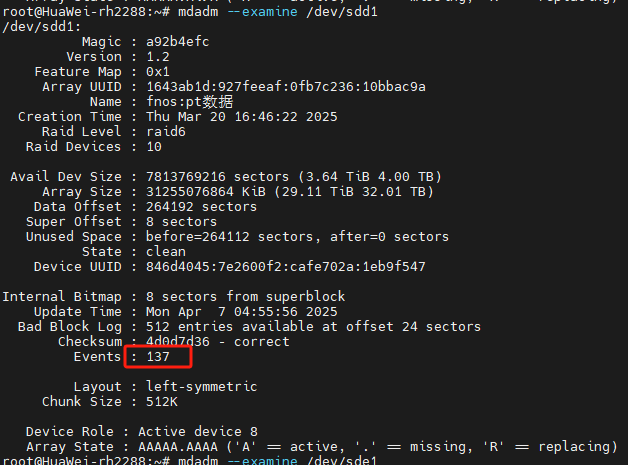
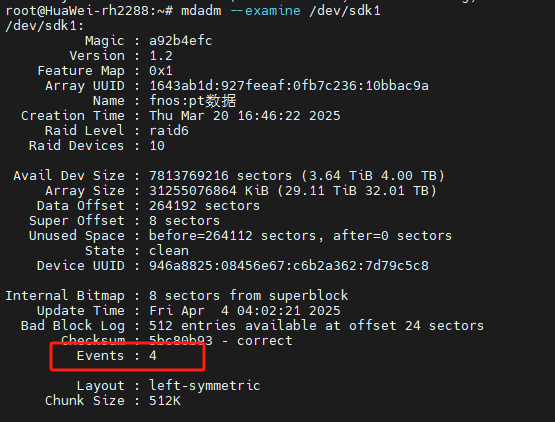
关于events的解释如下:
在 Linux 的 mdadm 软件 RAID 中,Events 值记录了阵列元数据的更新次数。每次阵列发生配置变更(如创建、重组、磁盘添加/移除、同步事件等),Events 值会递增。通过 mdadm –examine /dev/sdX 查看的 Events 值反映了该成员磁盘参与的阵列事件次数。
Events值不一致:表示这些磁盘的元数据更新次数不同,可能部分磁盘未同步或状态异常。- 典型原因:
- 某些磁盘离线时间较长,未参与最近的阵列操作。
- 磁盘被替换后未完成同步(或同步中断)。
- 磁盘存在硬件故障,导致元数据无法更新。
- 阵列处于降级或恢复状态。
156的sdf与其他盘仅差距1,可以认为是好盘。那么就可以尝试手动将这8块盘(除了sdd和sdk的8快)强制启动阵列,运气好的话阵列(raid6)就可以降级的形式启动了。
停止阵列
mdadm --stop /dev/md127
手动启动降级的阵列
只启动10块盘中的8块
mdadm --assemble --force -v /dev/md127 /dev/sda1 /dev/sdb1 /dev/sdc1 /dev/sde1 /dev/sdf1 /dev/sdg1 /dev/sdh1 /dev/sdi1
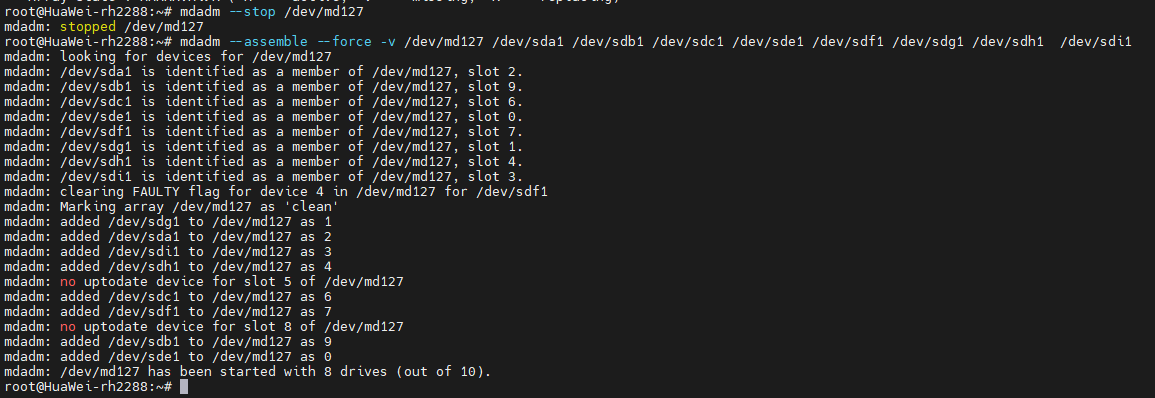
可以看到提示成功,已经启动了。
网页操作
刷新浏览器如下图,存储空间2已经回来了,只是缺了2块盘,我们暂时不管它。
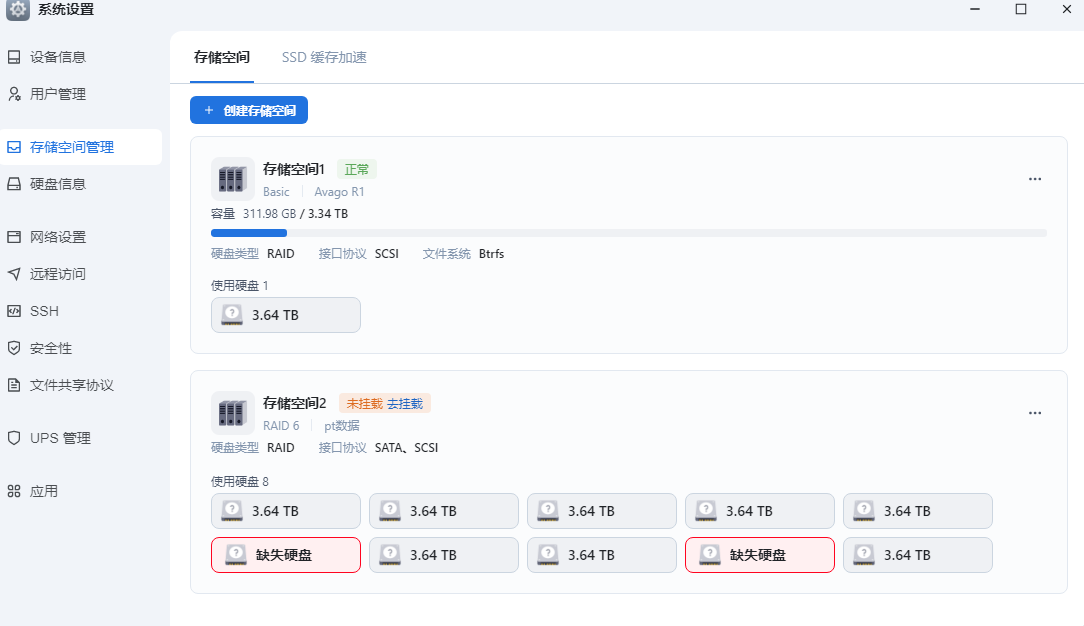
点击“去挂载”
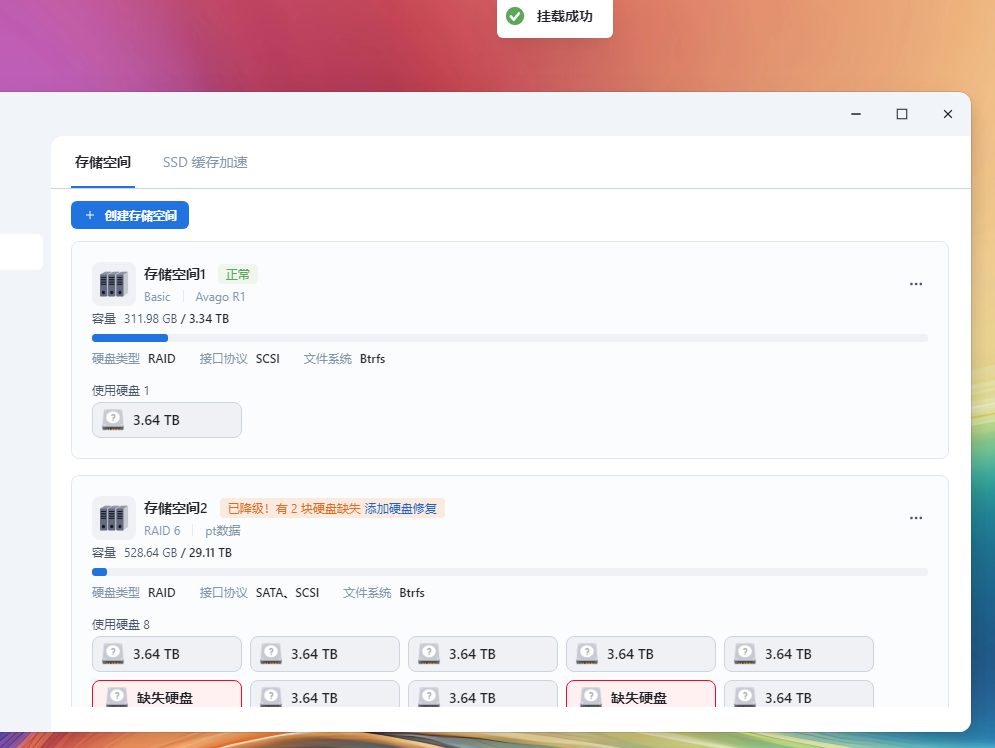
挂载成功后添加硬盘修复
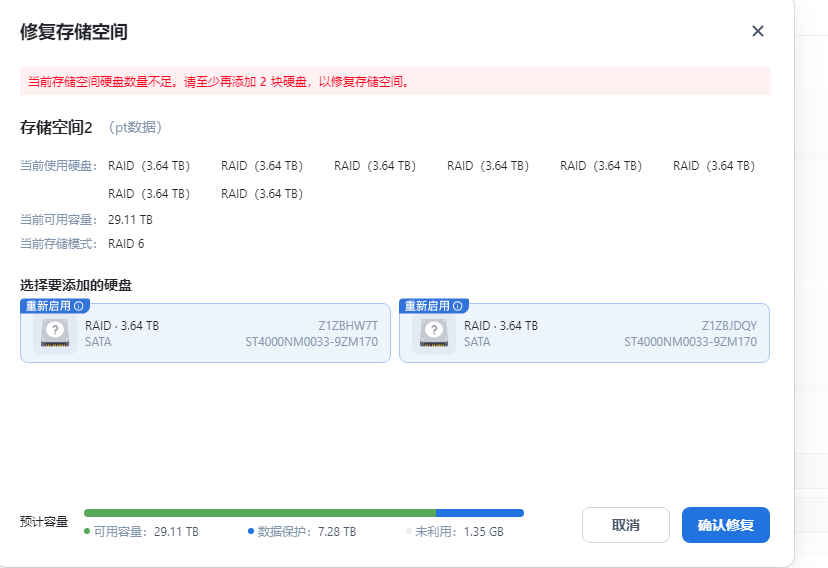
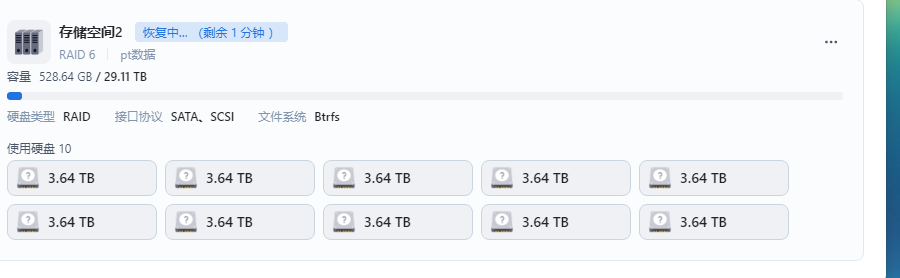
很快,说明实际并没有丢失数据,只是硬盘events状态问题
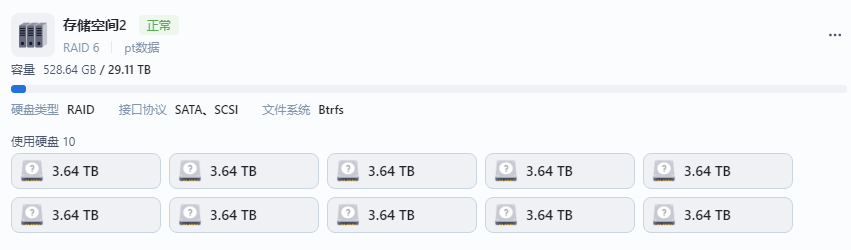
飞牛阵列掉盘,提示存储空间已移除

